

")

")



[ad_1]
This text used to be at first printed by means of Ampere Computing.
I noticed a weblog publish about gprofng, a brand new GNU profiling instrument. The instance in that weblog used to be a matrix-vector multiplication program written in C. I’m a Java™ programmer, and profiling Java programs is regularly tricky with equipment which can be designed for statically-compiled C systems, slightly than Java systems which can be compiled at runtime. On this weblog I display that gprofng is straightforward to make use of and helpful for digging into the dynamic habits of a Java software.
Step one used to be to put in writing a matrix multiplication program. I wrote a complete matrix-times-matrix program as a result of it isn’t harder than matrix-times-vector. There are 3 important strategies: one approach to compute the inner-most multiply-add, one approach to mix multiply-adds right into a unmarried part of the outcome, and one approach to iterate computing every part of the outcome.
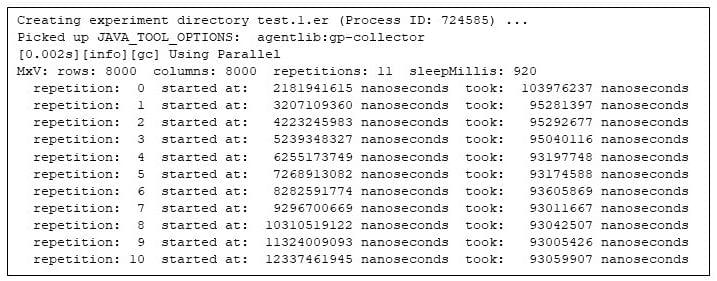
I wrapped the computation in a easy harness to compute the matrix product time and again, to ensure the days are repeatable. (See Finish Notice 1.) This system prints out when every matrix multiplication begins (relative to the beginning of the Java digital device), and the way lengthy every matrix multiply takes. Right here I ran the check to multiply two 8000×8000 matrices. The harness repeats the computation 11 occasions, and to higher spotlight the habits later, sleeps for 920 milliseconds between the repetitions:
$ numactl --cpunodebind=0 --membind=0 --
java -XX:+UseParallelGC -Xms31g -Xmx31g -Xlog:gc -XX:-UsePerfData
MxV -m 8000 -n 8000 -r 11 -s 920

Determine 1: Operating the matrix multiply program
Notice that the second one repetition takes 92% of the time of the primary repetition, and the final repetition takes best 89% of the primary repetition. Those permutations within the execution occasions ascertain that Java systems want a while to heat up.
The query is: Can I exploit gprofng to peer what is occurring between the primary repetition and the final repetition that makes the efficiency fortify?
A technique to reply to that query is to run this system and let gprofng acquire details about the run. Thankfully, this is simple: I merely prefix the command line with a gprofng command to gather what gprofng calls an “experiment.”:
$ numactl --cpunodebind=0 --membind=0 --
gprofng acquire app
java -XX:+UseParallelGC -Xms31g -Xmx31g -Xlog:gc --XX:-UsePerfData
MxV -m 8000 -n 8000 -r 11 -s 920
Determine 2: Operating the matrix multiply program underneath gprofng
The very first thing to notice, as with every profiling instrument, is the overhead that collecting profiling data imposes at the software. In comparison to the former, unprofiled run, gprofng turns out to impose no noticeable overhead.
I will be able to then ask gprofng how the time used to be spent in all of the software. (See Finish Notice 2.) For the entire run, gprofng says the most up to date 24 strategies are:
$ gprofng show textual content check.1.er -viewmode knowledgeable -limit 24 -functions
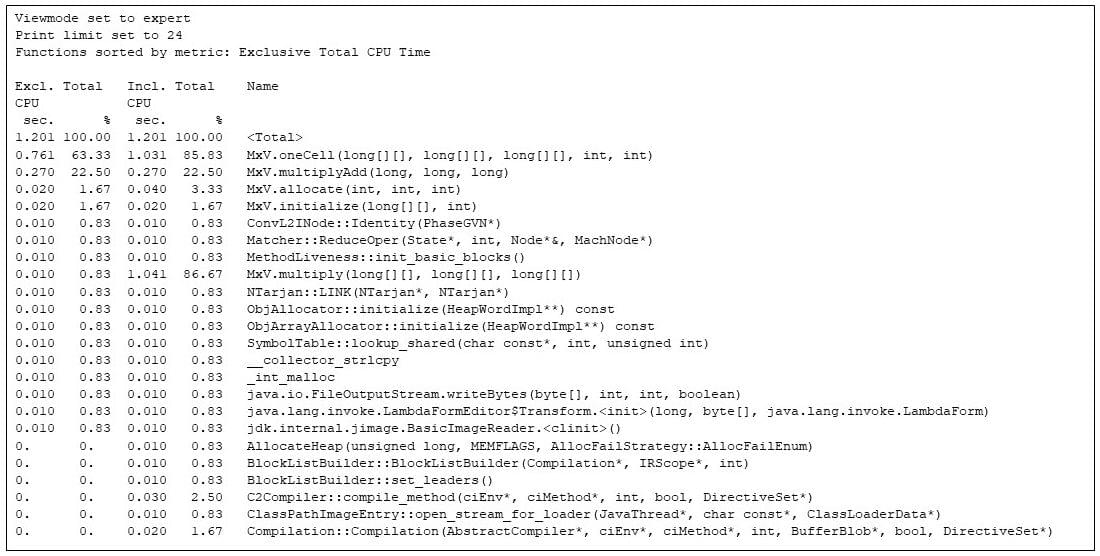
Determine 3: Gprofng show of the most up to date 24 strategies
The applications view proven above provides the unique and inclusive CPU occasions for every manner, each in seconds and as a share of the entire CPU time. The serve as named is a pseudo serve as generated by means of gprofng and has the entire price of the quite a lot of metrics. On this case I see that the entire CPU time spent at the entire software is 1.201 seconds.
The strategies of the appliance (the strategies from the category MxV) are in there, taking over the majority of the CPU time, however there are another strategies in there, together with the runtime compiler of the JVM (Compilation::Compilation), and different applications that don’t seem to be a part of the matrix multiplier. This show of the entire program execution captures the allocation (MxV.allocate) and initialization (MxV.initialize) code, which I’m much less concerned with since they’re a part of the check harness, are best used throughout start-up, and feature little to do with matrix multiplication.
I will be able to use gprofng to concentrate on the portions of the appliance that I’m concerned with. One of the crucial glorious options of gprofng is that once collecting an experiment, I will be able to follow filters to the accrued knowledge. For instance, to have a look at what used to be taking place throughout a selected period of time, or whilst a selected manner is at the name stack. For demonstration functions and to make the filtering more straightforward, I added strategic calls to Thread.sleep(ms) in order that it might be more straightforward to put in writing filters in keeping with program stages separated by means of one-second durations. For this reason this system output above in Determine 1 has every repetition separated by means of about one moment even if every matrix more than one takes best about 0.1 seconds.
gprofng is scriptable, so I wrote a script to extract particular person seconds from the gprofng experiment. The primary moment is all about Java digital device startup.
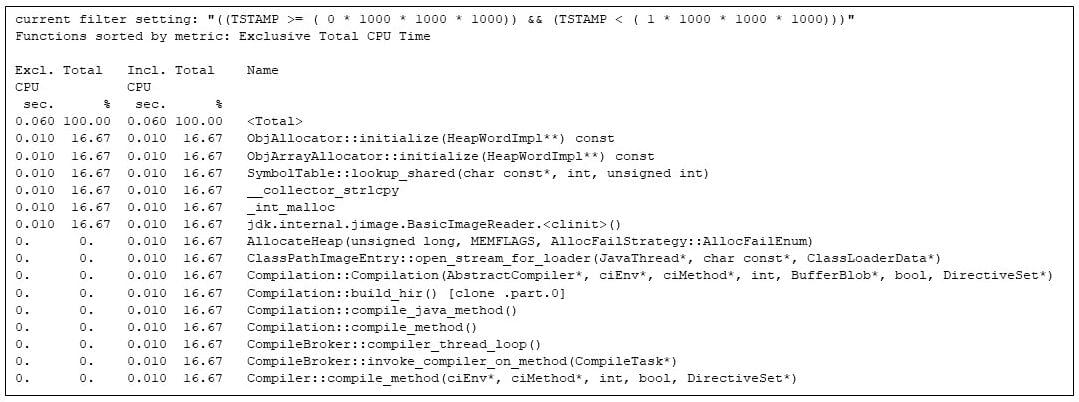
Determine 4: Filtering the most up to date strategies within the first moment. The matrix multiply has been artificially not on time throughout this moment to permit me to turn the JVM to begin up
I will be able to see that the runtime compiler is kicking in (e.g., Compilation::compile_java_method, taking 16% of the CPU time), even if not one of the strategies from the appliance has begun working. (The matrix multiplication calls are not on time by means of the sleep calls I inserted.)
After the primary moment is a moment throughout which the allocation and initialization strategies run, along side quite a lot of JVM strategies, however not one of the matrix multiply code has began but.
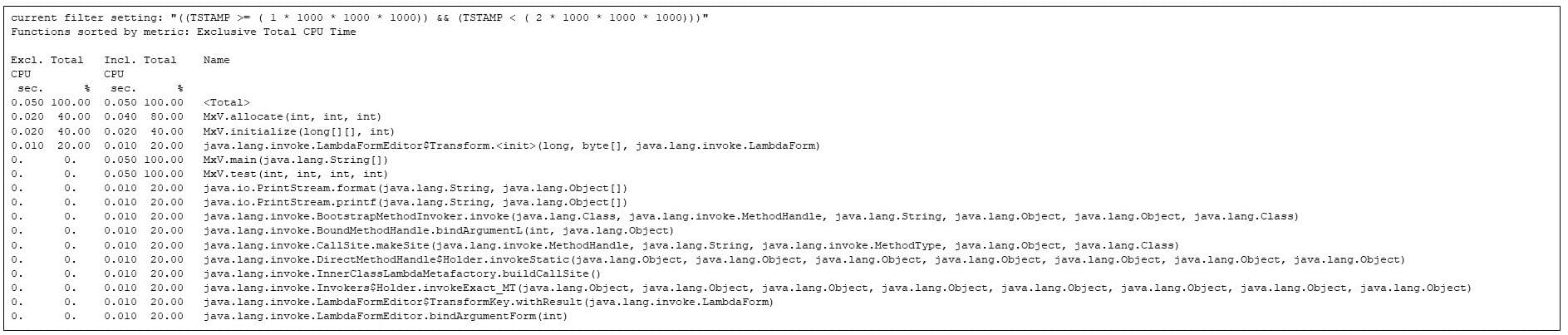
Determine 5: The most up to date strategies in the second one moment. The matrix allocation and initialization is competing with JVM startup
Now that JVM startup and the allocation and initialization of the arrays is done, the 3rd moment has the primary repetition of the matrix multiply code, proven in Determine 6. However notice that the matrix multiply code is competing for device assets with the Java runtime compiler (e.g., CompileBroker::invoke_compiler_on_method, 8% in Determine 6), which is compiling strategies because the matrix multiply code is located to be scorching.
Even so, the matrix multiplication code (e.g., the “inclusive” time within the MxV.major manner, 91%) is getting the majority of the CPU time. The inclusive time says {that a} matrix multiply (e.g., MxV.multiply) is taking 0.100 CPU seconds, which is of the same opinion with the wall time reported by means of the appliance in Determine 2. (Amassing and reporting the wall time takes some wall time, which is out of doors the CPU time gprofng accounts to MxV.multiply.)
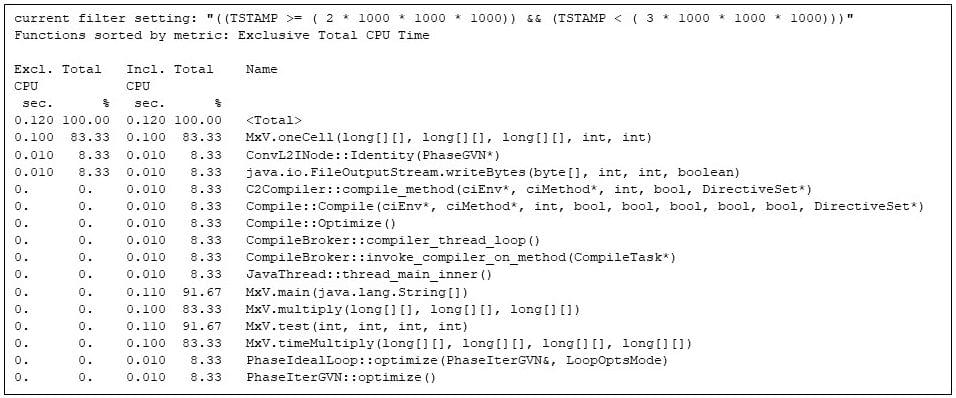
Determine 6: The most up to date strategies within the 3rd moment, appearing that the runtime compiler is competing with the matrix multiply strategies
On this explicit instance the matrix multiply isn’t in point of fact competing for CPU time, since the check is working on a multi-processor machine with quite a few idle cycles and the runtime compiler runs as separate threads. In a extra constrained cases, as an example on a heavily-loaded shared device, that 8% of the time spent within the runtime compiler may well be a subject. Alternatively, time spent within the runtime compiler produces extra environment friendly implementations of the strategies, so if I had been computing many matrix multiplies this is an funding I’m keen to make.
Via the 5th moment the matrix multiply code has the Java digital device to itself.
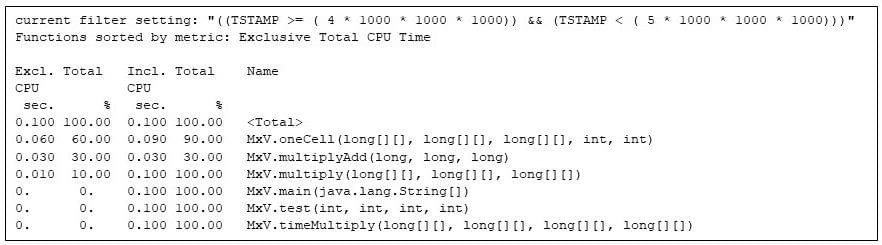
Determine 7: The entire working strategies throughout the 5th moment, appearing that best the matrix multiply strategies are energetic
Notice the 60%/30%/10% cut up in unique CPU seconds between MxV.oneCell, MxV.multiplyAdd, and MxV.multiply. The MxV.multiplyAdd manner merely computes a multiply and an addition: however it’s the innermost manner within the matrix multiply. MxV.oneCell has a loop that calls MxV.multiplyAdd. I will be able to see that the loop overhead and the decision (comparing conditionals and transfers of regulate) are reasonably extra paintings than the instantly mathematics in MxV.multiplyAdd. (This distinction is mirrored within the unique time for MxV.oneCell at 0.060 CPU seconds, in comparison to 0.030 CPU seconds for MxV.multiplyAdd.) The outer loop in MxV.multiply executes sometimes sufficient that the runtime compiler has now not but compiled it, however that manner is the usage of 0.010 CPU seconds.
Matrix multiplies proceed till the 9th moment, when the JVM runtime compiler kicks in once more, having found out that MxV.multiply has turn out to be scorching.
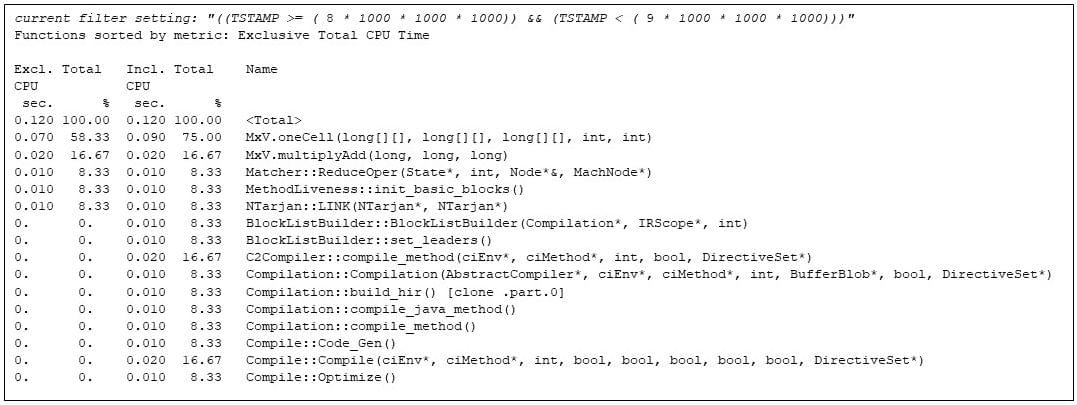
Via the overall repetition, the matrix multiplication code has complete use of the Java digital device.
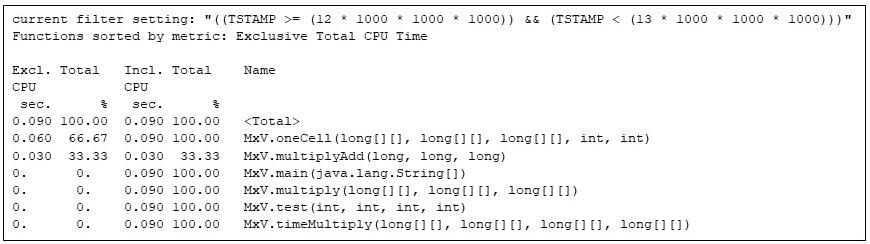
Determine 9: The overall repetition of the matrix multiply program, appearing the overall configuration of the code
Conclusion
I’ve proven how simple it’s to realize perception into the runtime of Java programs by means of profiling with gprofng. The use of the filtering function of gprofng to inspect an experiment by means of time slices allowed me to inspect simply this system stages of hobby. For instance, aside from allocation and initialization stages of the appliance, and exhibiting only one repetition of this system whilst the runtime compiler is operating its magic, which allowed me to spotlight the making improvements to efficiency as the recent code used to be gradually compiled.
Additional Studying
For readers who need to be told extra about gprofng, there may be this weblog publish with an introductory video on gprofng, together with directions on set up it on Oracle Linux.
Acknowledgements
Because of Ruud van der Pas, Kurt Goebel, and Vladimir Mezentsev for ideas and technical beef up, and to Elena Zannoni, David Banman, Craig Hardy, and Dave Neary for encouraging me to put in writing this weblog.
Finish Notes
1. The motivations for the parts of this system command line are:
numactl --cpunodebind=0 --membind=0 --. Limit the reminiscence utilized by the Java digital device to cores and reminiscence of 1 NUMA node. Proscribing the JVM to at least one node reduces run-to-run variation of this system.java. I’m the usage of OpenJDK construct of jdk-17.0.4.1 for aarch64.-XX:+UseParallelGC. Allow the parallel rubbish collector, as it does the least background paintings of the to be had creditors.-Xms31g -Xmx31g. Supply enough Java object heap house to by no means want a rubbish assortment.-Xlog:gc. Log the GC task to make sure {that a} assortment is certainly now not wanted. (“Consider however test.”)-XX: -UsePerfData. Decrease the Java digital device overhead.
2. The reasons of the gprofng choices are:
-limit 24. Display best the highest 24 strategies (right here taken care of by means of unique CPU time). I will be able to see that the show of 24 strategies will get me neatly down into the strategies that use nearly no time. Later I can use restrict 16 in puts the place 16 strategies get right down to the strategies that give a contribution insignificant quantities of CPU time. In one of the vital examples,gprofngitself limits the show, as a result of there don’t seem to be that many strategies that collect time.-viewmode knowledgeable. Display all of the strategies that collect CPU time, now not simply Java strategies, together with strategies which can be local to the JVM itself. The use of this flag lets in me to peer the runtime compiler strategies, and so on.
[ad_2]


