[ad_1]
On this instructional, we’ll discover the way to analyze huge textual content datasets with LangChain and Python to search out attention-grabbing knowledge in anything else from books to Wikipedia pages.
AI is this kind of giant subject in this day and age that OpenAI and libraries like LangChain slightly want any advent. However, when you’ve been misplaced in an alternative size for the previous yr or so, LangChain, in a nutshell, is a framework for growing programs powered by means of language fashions, permitting builders to make use of the facility of LLMs and AI to research knowledge and construct their very own AI apps.
Use Instances
Prior to entering the entire technicalities, I believe it’s great to take a look at some use instances of textual content dataset research the use of LangChain. Listed here are some examples:
- Systematically extracting helpful knowledge from lengthy paperwork.
- Visualizing traits inside a textual content or textual content dataset.
- Making summaries for lengthy and boring texts.
Necessities
To observe in conjunction with this newsletter, create a brand new folder and set up LangChain and OpenAI the use of pip:
pip3 set up langchain openai
Document Studying, Textual content Splitting and Information Extraction
To research huge texts, reminiscent of books, you wish to have to separate the texts into smaller chunks. It is because huge texts, reminiscent of books, include loads of hundreds to thousands and thousands of tokens, and taking into consideration that no LLM can procedure that many tokens at a time, there’s no approach to analyze such texts as a complete with out splitting.
Additionally, as a substitute of saving particular person urged outputs for each and every bite of a textual content, it’s extra environment friendly to make use of a template for extracting knowledge and hanging it right into a structure like JSON or CSV.
On this instructional, I’ll be the use of JSON. This is the e book that I’m the use of for this case, which I downloaded totally free from Challenge Gutenberg. This code reads the e book Past Excellent and Evil by means of Friedrich Nietzsche, splits it into chapters, makes a abstract of the primary bankruptcy, extracts the philosophical messages, moral theories and ethical ideas offered within the textual content, and places all of it into JSON structure.
As you’ll see, I used the “gpt-3.5-turbo-1106” type to paintings with greater contexts of as much as 16000 tokens and a nil.3 temperature to offer it just a little of creativity. You’ll experiment with the temperature and spot what works easiest together with your use case.
Word: the temperature parameter determines the liberty of an LLM to make inventive and once in a while random solutions. The decrease the temperature, the extra factual the LLM output, and the upper the temperature, the extra inventive and random the LLM output.
The extracted knowledge will get put into JSON structure the use of create_structured_output_chain and the supplied JSON schema:
json_schema = {
"sort": "object",
"homes": {
"abstract": {"name": "Abstract", "description": "The bankruptcy abstract", "sort": "string"},
"messages": {"name": "Messages", "description": "Philosophical messages", "sort": "string"},
"ethics": {"name": "Ethics", "description": "Moral theories and ethical ideas offered within the textual content", "sort": "string"}
},
"required": ["summary", "messages", "ethics"],
}
chain = create_structured_output_chain(json_schema, llm, urged, verbose=False)
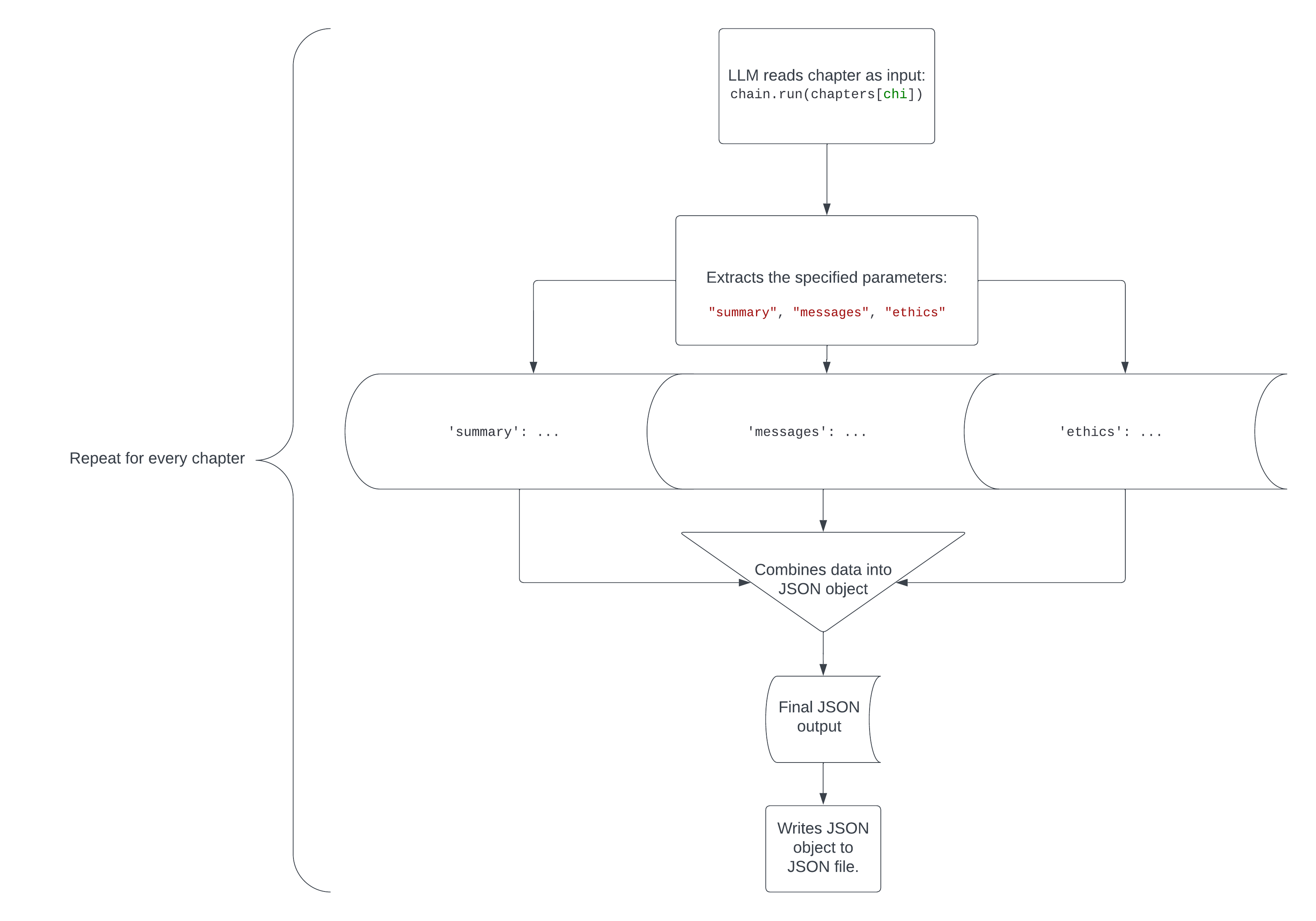
The code then reads the textual content record containing the e book and splits it by means of bankruptcy. The chain is then given the primary bankruptcy of the e book as textual content enter:
f = open("texts/Past Excellent and Evil.txt", "r")
phi_text = str(f.learn())
chapters = phi_text.break up("CHAPTER")
print(chain.run(chapters[1]))
Right here’s the output of the code:
{'abstract': 'The bankruptcy discusses the concept that of utilitarianism and its software in moral decision-making. It explores the theory of maximizing general happiness and minimizing struggling as an ethical theory. The bankruptcy additionally delves into the criticisms of utilitarianism and the demanding situations of making use of it in real-world situations.', 'messages': 'The bankruptcy emphasizes the significance of taking into consideration the effects of our movements and the well-being of all people affected. It encourages considerate and empathetic decision-making, bearing in mind the wider affect on society.', 'ethics': 'The moral theories offered within the textual content come with consequentialism, hedonistic utilitarianism, and the primary of the best excellent for the best quantity.'}
Lovely cool. Philosophical texts written 150 years in the past are lovely onerous to learn and perceive, however this code right away translated the details from the primary bankruptcy into an easy-to-understand record of the bankruptcy’s abstract, message and moral theories/ethical ideas. The flowchart under provides you with a visible illustration of what occurs on this code.

Now you’ll do the similar for the entire chapters and put the whole lot right into a JSON record the use of this code.
I added time.sleep(20) as feedback, because it’s conceivable that you just’ll hit fee limits when running with huge texts, in all probability if in case you have the loose tier of the OpenAI API. Since I believe it’s at hand to understand how many tokens and credit you’re the use of together with your requests in order to not unintentionally drain your account, I extensively utilized with get_openai_callback() as cb: to look what number of tokens and credit are used for each and every bankruptcy.
That is the a part of the code that analyzes each and every bankruptcy and places the extracted knowledge for each and every in a shared JSON record:
for chi in vary(1, len(chapters), 1):
with get_openai_callback() as cb:
ch = chain.run(chapters[chi])
print(cb)
print("n")
print(ch)
print("nn")
json_object = json.dumps(ch, indent=4)
if chi == 1:
with open("Past Excellent and Evil.json", "w") as outfile:
outfile.write("[n"+json_object+",")
elif chi < len(chapters)-1:
with open("Beyond Good and Evil.json", "a") as outfile:
outfile.write(json_object+",")
else:
with open("Beyond Good and Evil.json", "a") as outfile:
outfile.write(json_object+"n]")
The chi index begins at 1, as a result of there’s no bankruptcy 0 earlier than bankruptcy 1. If the chi index is 1 (at the first bankruptcy), the code writes (overwrites any present content material) the JSON knowledge to the record whilst additionally including a gap sq. bracket and new line firstly, and a comma on the finish to observe JSON syntax. If chi isn’t the minimal price (1) or most price (len(chapters)-1), the JSON knowledge simply will get added to the record in conjunction with a comma on the finish. In spite of everything, if chi is at its most price, the JSON will get added to the JSON record with a brand new line and shutting sq. bracket.
After the code finishes working, you’ll see that Past Excellent and Evil.json is full of the extracted data from the entire chapters.
Right here’s a visible illustration of ways this code works.
Running With A couple of Recordsdata
In case you have dozens of separate information that you just’d like to research one after the other, you’ll use a script very similar to the only you’ve simply observed, however as a substitute of iterating via chapters, it’ll iterate via information in a folder.
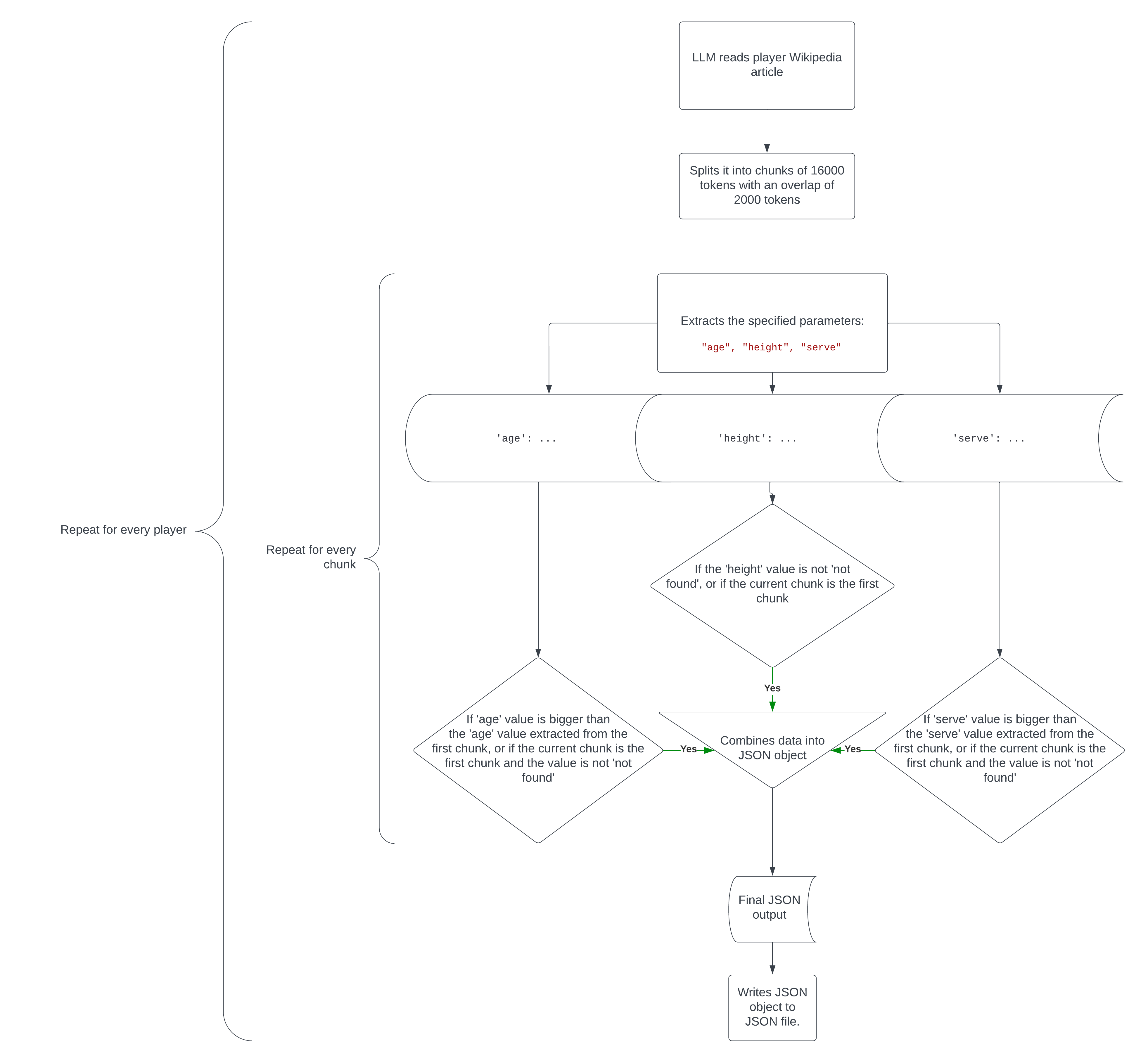
I’ll use the instance of a folder stuffed with Wikipedia articles at the most sensible 10 ranked tennis avid gamers (as of December 3 2023) known as top_10_tennis_players. You’ll obtain the folder right here. This code will learn each and every Wikipedia article, extract each and every participant’s age, top and quickest serve in km/h and put the extracted knowledge right into a JSON record in a separate folder known as player_data.
Right here’s an instance of an extracted participant knowledge record.

On the other hand, this code isn’t that easy (I want it used to be). To successfully and reliably extract essentially the most correct knowledge from texts which are regularly too giant to research with out bite splitting, I used this code:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=16000,
chunk_overlap=2000,
length_function=len,
add_start_index=True,
)
sub_texts = text_splitter.create_documents([player_text])
ch = []
for ti in vary(len(sub_texts)):
with get_openai_callback() as cb:
ch.append(chain.run(sub_texts[ti]))
print(ch[-1])
print(cb)
print("n")
for chi in vary(1, len(ch), 1):
if (ch[chi]["age"] > ch[0]["age"]) or (ch[0]["age"] == "now not discovered" and ch[chi]["age"] != "now not discovered"):
ch[0]["age"] = ch[chi]["age"]
ruin
if (ch[chi]["serve"] > ch[0]["serve"]) or (ch[0]["serve"] == "now not discovered" and ch[chi]["serve"] != "now not discovered"):
ch[0]["serve"] = ch[chi]["serve"]
ruin
if (ch[0]["height"] == "now not discovered") and (ch[chi]["height"] != "now not discovered"):
ch[0]["height"] = ch[chi]["height"]
ruin
else:
proceed
In essence, this code does the next:
- It splits the textual content into chunks 16000 tokens in dimension, with a bit overlap of 2000 to stay just a little of context.
- it extracts the required knowledge from each and every bite.
- If the information extracted from the newest bite is extra related or correct than that of the primary bite (or the price isn’t discovered within the first bite however is located in the newest bite), it adjusts the values of the primary bite. For instance, if bite 1 says
'age': 26and bite 2 says'age': 27, theageprice gets up to date to 27 since we want the participant’s newest age, or if bite 1 says'serve': 231and bite 2 says'serve': 232, theserveprice gets up to date to 232 since we’re in search of the quickest serve pace.
Right here’s how the entire code works in a flowchart.
Textual content to Embeddings
Embeddings are vector lists which are used to affiliate items of textual content with each and every different.
A large side of textual content research in LangChain is looking out huge texts for particular chunks which are related to a definite enter or query.
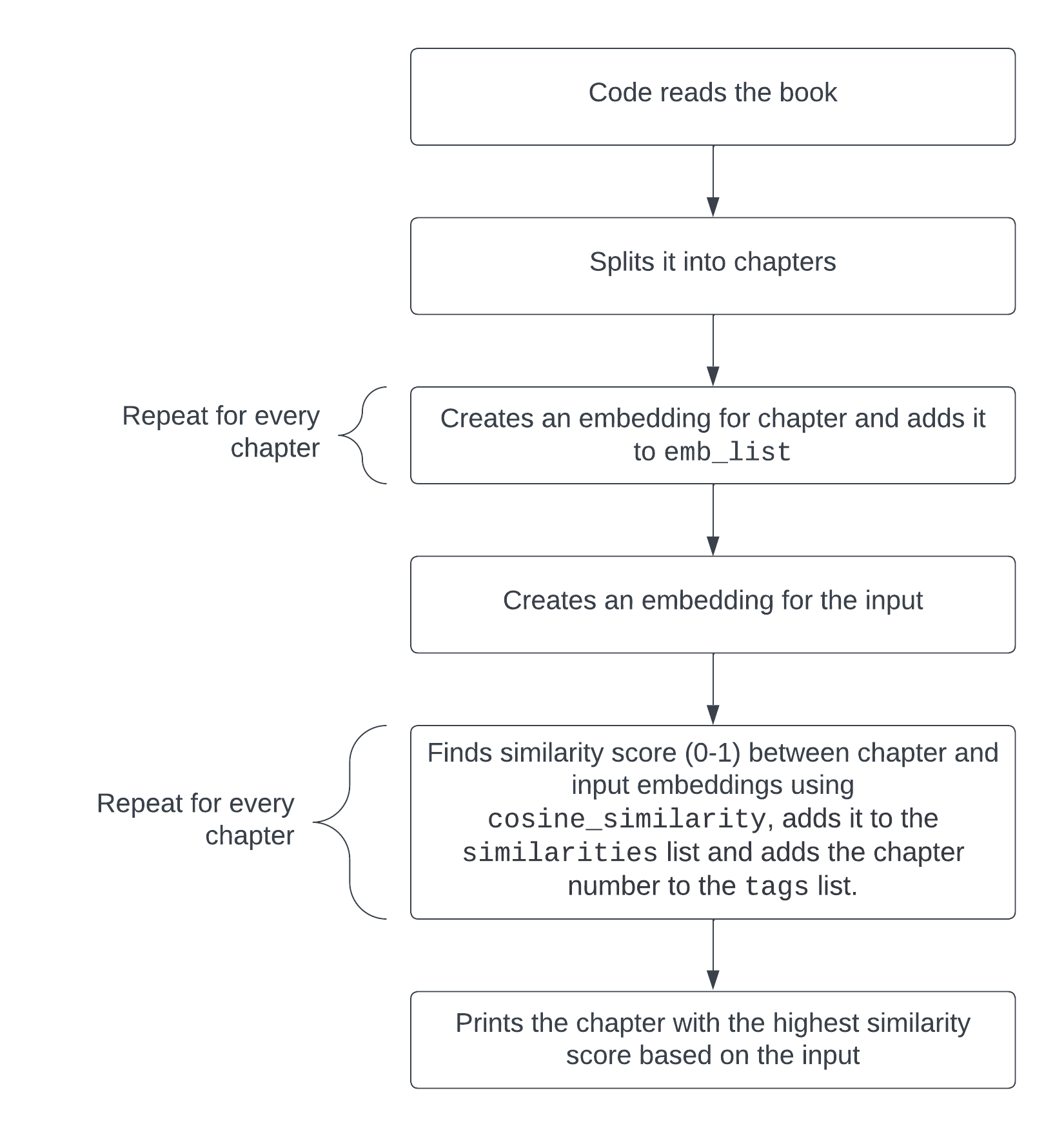
We will return to the instance with the Past Excellent and Evil e book by means of Friedrich Nietzsche and make a easy script that takes a query at the textual content like “What are the failings of philosophers?”, turns it into an embedding, splits the e book into chapters, turns the other chapters into embeddings and reveals the bankruptcy maximum related to the inquiry, suggesting which bankruptcy one will have to learn to search out a solution to this query as written by means of the writer. You’ll in finding the code to try this right here. This code particularly is what searches for essentially the most related bankruptcy for a given enter or query:
embedded_question = embeddings_model.embed_query("What are the failings of philosophers?")
similarities = []
tags = []
for i2 in vary(len(emb_list)):
similarities.append(cosine_similarity(emb_list[i2], embedded_question))
tags.append(f"CHAPTER {i2}")
print(tags[similarities.index(max(similarities))])
The embeddings similarities between each and every bankruptcy and the enter get put into a listing (similarities) and the selection of each and every bankruptcy will get put into the tags record. Essentially the most related bankruptcy is then published the use of print(tags[similarities.index(max(similarities))]), which will get the bankruptcy quantity from the tags record that corresponds to the utmost price from the similarities record.
Output:
CHAPTER 1
Right here’s how this code works visually.
Different Software Concepts
There are lots of different analytical makes use of for enormous texts with LangChain and LLMs, and even supposing they’re too advanced to hide on this article of their entirety, I’ll record a few of them and description how they are able to be completed on this segment.
Visualizing subjects
You’ll, as an example, take transcripts of YouTube movies associated with AI, like those in this dataset, extract the AI similar equipment discussed in each and every video (LangChain, OpenAI, TensorFlow, and so forth), assemble them into a listing, and in finding the entire maximum discussed AI equipment, or use a bar graph to visualise the recognition of each and every one.
Examining podcast transcripts
You’ll take podcast transcripts and, as an example, in finding similarities and variations between the other visitors on the subject of their reviews and sentiment on a given subject. You’ll additionally make an embeddings script (like the only on this article) that searches the podcast transcripts for essentially the most related conversations in keeping with an enter or query.
Examining evolutions of reports articles
There are many huge information article datasets in the market, like this one on BBC information headlines and outlines and this one on monetary information headlines and outlines. The usage of such datasets, you’ll analyze such things as sentiment, subjects and key phrases for each and every information article. You’ll then visualize how those facets of the inside track articles evolve over the years.
Conclusion
I’m hoping you discovered this useful and that you just now have an concept of the way to analyze huge textual content datasets with LangChain in Python the use of other strategies like embeddings and information extraction. Very best of good fortune to your LangChain initiatives!
[ad_2]