
[ad_1]
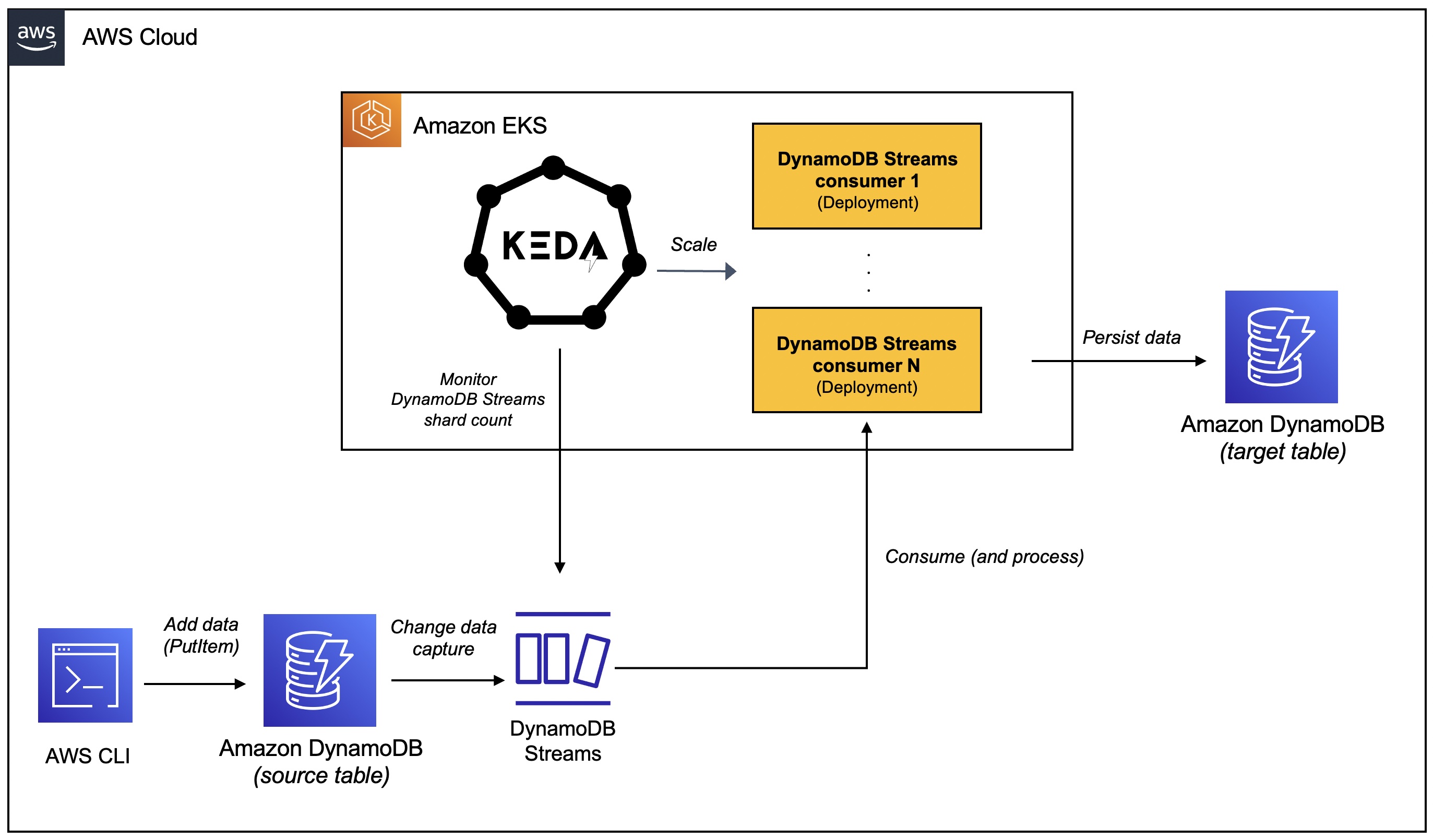
This weblog publish demonstrates learn how to auto-scale your DynamoDB Streams person programs on Kubernetes. You are going to paintings with a Java software that makes use of the DynamoDB Streams Kinesis adapter library to eat exchange knowledge occasions from a DynamoDB desk. It’ll be deployed to an Amazon EKS cluster and shall be scaled mechanically the usage of KEDA.
The applying comprises an implementation of the com.amazonaws.products and services.kinesis.clientlibrary.interfaces.v2.IRecordProcessor that processes knowledge from the DynamoDB flow and replicates it to any other (goal) DynamoDB desk – that is simply used for example. We can use the AWS CLI to provide knowledge to the DynamoDB flow and apply the scaling of the applying.
The code is to be had on this GitHub repository.
What is Coated?
- Advent
- Horizontal scalability with Kinesis Shopper Library
- What’s KEDA?
- Must haves
- Setup and configure KEDA on EKS
- Configure IAM Roles
- Deploy DynamoDB Streams person software to EKS
- DynamoDB Streams person app autoscaling in motion with KEDA
- Delete sources
- Conclusion
Advent
Amazon DynamoDB is a completely controlled database provider that gives speedy and predictable efficiency with seamless scalability. With DynamoDB Streams, you’ll leverage Exchange Knowledge Seize (CDC) to get notified about adjustments to DynamoDB desk knowledge in actual time. This makes it imaginable to simply construct programs that react to adjustments within the underlying database with out the will for advanced polling or querying.
DynamoDB gives two streaming fashions for exchange knowledge seize:
- Kinesis Knowledge Streams for DynamoDB
- DynamoDB Streams
With Kinesis Knowledge Streams, you’ll seize item-level changes in any DynamoDB desk and reflect them to a Kinesis knowledge flow. With DynamoDB Streams captures a time-ordered series of item-level changes in any DynamoDB desk and retail outlets this knowledge in a log for as much as 24 hours.
We can employ the local DynamoDB Streams capacity. Even with DynamoDB Streams, there are more than one choices to choose between in the case of eating the exchange knowledge occasions:
Our software will leverage DynamoDB Streams at the side of the Kinesis Shopper Library (KCL) adapter library 1.x to eat exchange knowledge occasions from a DynamoDB desk.
Horizontal Scalability With Kinesis Shopper Library
The Kinesis Shopper Library guarantees that for each and every shard there’s a document processor operating and processing that shard. KCL is helping deal with most of the advanced duties related to dispensed computing and scalability. It connects to the information flow, enumerates the shards throughout the knowledge flow, and makes use of rentals to coordinate shard associations with its person programs.
A document processor is instantiated for each and every shard it manages. KCL pulls knowledge data from the information flow, pushes the data to the corresponding document processor, and checkpoints processed data. Extra importantly, it balances shard-worker associations (rentals) when the employee example rely adjustments or when the information flow is re-sharded (shards are break up or merged). Because of this you’ll be able to scale your DynamoDB Streams software by means of merely including extra cases since KCL will mechanically steadiness the shards around the cases.
However, you continue to desire a technique to scale your programs when the weight will increase. After all, you must do it manually or construct a customized method to get this executed.
That is the place KEDA is available in.
What Is KEDA?
KEDA is a Kubernetes-based event-driven autoscaling part that may observe occasion resources like DynamoDB Streams and scale the underlying Deployments (and Pods) in response to the choice of occasions desiring to be processed. It is constructed on most sensible of local Kubernetes primitives such because the Horizontal Pod Autoscaler that may be added to any Kubernetes cluster. Here’s a high-level evaluation of its key elements (you’ll check with the KEDA documentation for a deep dive):
 From
From - The
keda-operator-metrics-apiserverpart inKEDAacts as a Kubernetes metrics server that exposes metrics for the Horizontal Pod Autoscaler. - A KEDA Scaler integrates with an exterior gadget (reminiscent of Redis) to fetch those metrics (e.g., duration of an inventory) to force auto-scaling of any container in Kubernetes in response to the choice of occasions desiring to be processed.
- The position of the
keda-operatorpart is to turn on and deactivateDeployment, i.e. scale to and from 0.
You are going to see the DynamoDB Streams scaler in motion that scales in response to the shard rely of a DynamoDB Circulate.
Now let’s transfer directly to the sensible a part of this instructional.
Must haves
Along with an AWS account, it is important to have the AWS CLI, kubectl, and Docker put in.
Setup an EKS Cluster and Create a DynamoDB Desk
There are a selection of the way during which you’ll create an Amazon EKS cluster. I desire the usage of eksctl CLI as a result of the ease it gives. Growing an EKS cluster the usage of eksctl can also be as simple as this:
eksctl create cluster --name <cluster call> --region <area e.g. us-east-1>
For main points, check with the Getting Began with Amazon EKS – eksctl.
Create a DynamoDB desk with streams enabled to persist software knowledge and get right of entry to the exchange knowledge feed. You’ll be able to use the AWS CLI to create a desk with the next command:
aws dynamodb create-table
--table-name customers
--attribute-definitions AttributeName=e-mail,AttributeType=S
--key-schema AttributeName=e-mail,KeyType=HASH
--billing-mode PAY_PER_REQUEST
--stream-specification StreamEnabled=true,StreamViewType=NEW_AND_OLD_IMAGES
We can wish to create any other desk that may function a reproduction of the primary desk.
aws dynamodb create-table
--table-name users_replica
--attribute-definitions AttributeName=e-mail,AttributeType=S
--key-schema AttributeName=e-mail,KeyType=HASH
--billing-mode PAY_PER_REQUEST
Clone this GitHub repository and alter it to the precise listing:
git clone https://github.com/abhirockzz/dynamodb-streams-keda-autoscale
cd dynamodb-streams-keda-autoscale
Adequate, let’s get began!
Setup and Configure KEDA on EKS
For the needs of this instructional, you’ll use YAML information to deploy KEDA, however you must additionally use Helm charts.
Set up KEDA:
# replace model 2.8.2 if required
kubectl follow -f https://github.com/kedacore/keda/releases/obtain/v2.8.2/keda-2.8.2.yaml
Check the set up:
# test Customized Useful resource Definitions
kubectl get crd
# test KEDA Deployments
kubectl get deployment -n keda
# test KEDA operator logs
kubectl logs -f $(kubectl get pod -l=app=keda-operator -o jsonpath="{.pieces[0].metadata.call}" -n keda) -n keda
Configure IAM Roles
The KEDA operator in addition to the DynamoDB streams person software wish to invoke AWS APIs. Since each will run as Deployments in EKS, we can use IAM Roles for Carrier Accounts (IRSA) to give you the vital permissions.
In our explicit state of affairs:
KEDAoperator wishes so to get details about the DynamoDB desk and Circulate- The applying (KCL 1.x library to be explicit) wishes to engage with Kinesis and DynamoDB – it wishes a bunch of IAM permissions to take action.
Configure IRSA for the KEDA Operator
Set your AWS Account ID and OIDC Identification supplier as surroundings variables:
ACCOUNT_ID=$(aws sts get-caller-identity --query "Account" --output textual content)
#replace the cluster call and area as required
export EKS_CLUSTER_NAME=demo-eks-cluster
export AWS_REGION=us-east-1
OIDC_PROVIDER=$(aws eks describe-cluster --name $EKS_CLUSTER_NAME --query "cluster.id.oidc.issuer" --output textual content | sed -e "s/^https:////")
Create a JSON record with Relied on Entities for the position:
learn -r -d '' TRUST_RELATIONSHIP <<EOF
{
"Model": "2012-10-17",
"Remark": [
{
"Effect": "Allow",
"Principal": {
"Federated": "arn:aws:iam::${ACCOUNT_ID}:oidc-provider/${OIDC_PROVIDER}"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"${OIDC_PROVIDER}:aud": "sts.amazonaws.com",
"${OIDC_PROVIDER}:sub": "system:serviceaccount:keda:keda-operator"
}
}
}
]
}
EOF
echo "${TRUST_RELATIONSHIP}" > trust_keda.json
Now, create the IAM position and fix the coverage (check out policy_dynamodb_streams_keda.json record for main points):
export ROLE_NAME=keda-operator-dynamodb-streams-role
aws iam create-role --role-name $ROLE_NAME --assume-role-policy-document record://trust_keda.json --description "IRSA for DynamoDB streams KEDA scaler on EKS"
aws iam create-policy --policy-name keda-dynamodb-streams-policy --policy-document record://policy_dynamodb_streams_keda.json
aws iam attach-role-policy --role-name $ROLE_NAME --policy-arn=arn:aws:iam::${ACCOUNT_ID}:coverage/keda-dynamodb-streams-policy
Affiliate the IAM position and Carrier Account:
kubectl annotate serviceaccount -n keda keda-operator eks.amazonaws.com/role-arn=arn:aws:iam::${ACCOUNT_ID}:position/${ROLE_NAME}
# examine the annotation
kubectl describe serviceaccount/keda-operator -n keda
It is very important restart KEDA operator Deployment for this to take impact:
kubectl rollout restart deployment.apps/keda-operator -n keda
# to make sure, verify that the KEDA operator has the precise surroundings variables
kubectl describe pod -n keda $(kubectl get po -l=app=keda-operator -n keda --output=jsonpath={.pieces..metadata.call}) | grep "^s*AWS_"
# anticipated output
AWS_STS_REGIONAL_ENDPOINTS: regional
AWS_DEFAULT_REGION: us-east-1
AWS_REGION: us-east-1
AWS_ROLE_ARN: arn:aws:iam::<AWS_ACCOUNT_ID>:position/keda-operator-dynamodb-streams-role
AWS_WEB_IDENTITY_TOKEN_FILE: /var/run/secrets and techniques/eks.amazonaws.com/serviceaccount/token
Configure IRSA for the DynamoDB Streams Shopper Software
Get started by means of making a Kubernetes Carrier Account:
kubectl follow -f - <<EOF
apiVersion: v1
sort: ServiceAccount
metadata:
call: dynamodb-streams-consumer-app-sa
EOF
Create a JSON record with Relied on Entities for the position:
learn -r -d '' TRUST_RELATIONSHIP <<EOF
{
"Model": "2012-10-17",
"Remark": [
{
"Effect": "Allow",
"Principal": {
"Federated": "arn:aws:iam::${ACCOUNT_ID}:oidc-provider/${OIDC_PROVIDER}"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"${OIDC_PROVIDER}:aud": "sts.amazonaws.com",
"${OIDC_PROVIDER}:sub": "system:serviceaccount:default:dynamodb-streams-consumer-app-sa"
}
}
}
]
}
EOF
echo "${TRUST_RELATIONSHIP}" > agree with.json
Now, create the IAM position and fix the coverage. Replace the coverage.json record and input the area and AWS account main points.
export ROLE_NAME=dynamodb-streams-consumer-app-role
aws iam create-role --role-name $ROLE_NAME --assume-role-policy-document record://agree with.json --description "IRSA for DynamoDB Streams person app on EKS"
aws iam create-policy --policy-name dynamodb-streams-consumer-app-policy --policy-document record://coverage.json
aws iam attach-role-policy --role-name $ROLE_NAME --policy-arn=arn:aws:iam::${ACCOUNT_ID}:coverage/dynamodb-streams-consumer-app-policy
Affiliate the IAM position and Carrier Account:
kubectl annotate serviceaccount -n default dynamodb-streams-consumer-app-sa eks.amazonaws.com/role-arn=arn:aws:iam::${ACCOUNT_ID}:position/${ROLE_NAME}
# examine the annotation
kubectl describe serviceaccount/dynamodb-streams-consumer-app-sa
The core infrastructure is now able. Let’s get ready and deploy the patron software.
Deploy DynamoDB Streams Shopper Software to EKS
We’d first wish to construct the Docker symbol and push it to ECR (you’ll check with the Dockerfile for main points).
Construct and Push the Docker Symbol to ECR
# create runnable JAR record
mvn blank bring together meeting:unmarried
# construct docker symbol
docker construct -t dynamodb-streams-consumer-app .
AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query "Account" --output textual content)
# create a personal ECR repo
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin $AWS_ACCOUNT_ID.dkr.ecr.us-east-1.amazonaws.com
aws ecr create-repository --repository-name dynamodb-streams-consumer-app --region us-east-1
# tag and push the picture
docker tag dynamodb-streams-consumer-app:newest $AWS_ACCOUNT_ID.dkr.ecr.us-east-1.amazonaws.com/dynamodb-streams-consumer-app:newest
docker push $AWS_ACCOUNT_ID.dkr.ecr.us-east-1.amazonaws.com/dynamodb-streams-consumer-app:newest
Deploy the Shopper Software
Replace the person.yaml to incorporate the Docker symbol you simply driven to ECR and the ARN for the DynamoDB streams for the supply desk. The remainder of the manifest stays the similar.
To retrieve the ARN for the flow, run the next command:
aws dynamodb describe-table --table-name customers | jq -r '.Desk.LatestStreamArn'
The person.yaml Deployment manifest looks as if this:
apiVersion: apps/v1
sort: Deployment
metadata:
call: dynamodb-streams-kcl-consumer-app
spec:
replicas: 1
selector:
matchLabels:
app: dynamodb-streams-kcl-consumer-app
template:
metadata:
labels:
app: dynamodb-streams-kcl-consumer-app
spec:
serviceAccountName: dynamodb-streams-kcl-consumer-app-sa
packing containers:
- call: dynamodb-streams-kcl-consumer-app
symbol: AWS_ACCOUNT_ID.dkr.ecr.us-east-1.amazonaws.com/dynamodb-streams-kcl-consumer-app:newest
imagePullPolicy: At all times
env:
- call: TARGET_TABLE_NAME
worth: users_replica
- call: APPLICATION_NAME
worth: dynamodb-streams-kcl-app-demo
- call: SOURCE_TABLE_STREAM_ARN
worth: <input ARN>
- call: AWS_REGION
worth: us-east-1
- call: INSTANCE_NAME
valueFrom:
fieldRef:
fieldPath: metadata.call
Create the Deployment:
kubectl follow -f person.yaml
# examine Pod transition to Working state
kubectl get pods -w
DynamoDB Streams Shopper App Autoscaling in Motion With KEDA
Now that you’ve got deployed the patron software, the KCL adapter library must leap into motion. The very first thing it’ll do is create a “keep watch over desk” in DynamoDB – it must be the similar because the call of the applying (which on this case is dynamodb-streams-kcl-app-demo).
It could take a couple of mins for the preliminary co-ordination to occur and the desk to get created. You’ll be able to test the logs of the patron software to peer the growth.
kubectl logs -f $(kubectl get po -l=app=dynamodb-streams-kcl-consumer-app --output=jsonpath={.pieces..metadata.call})
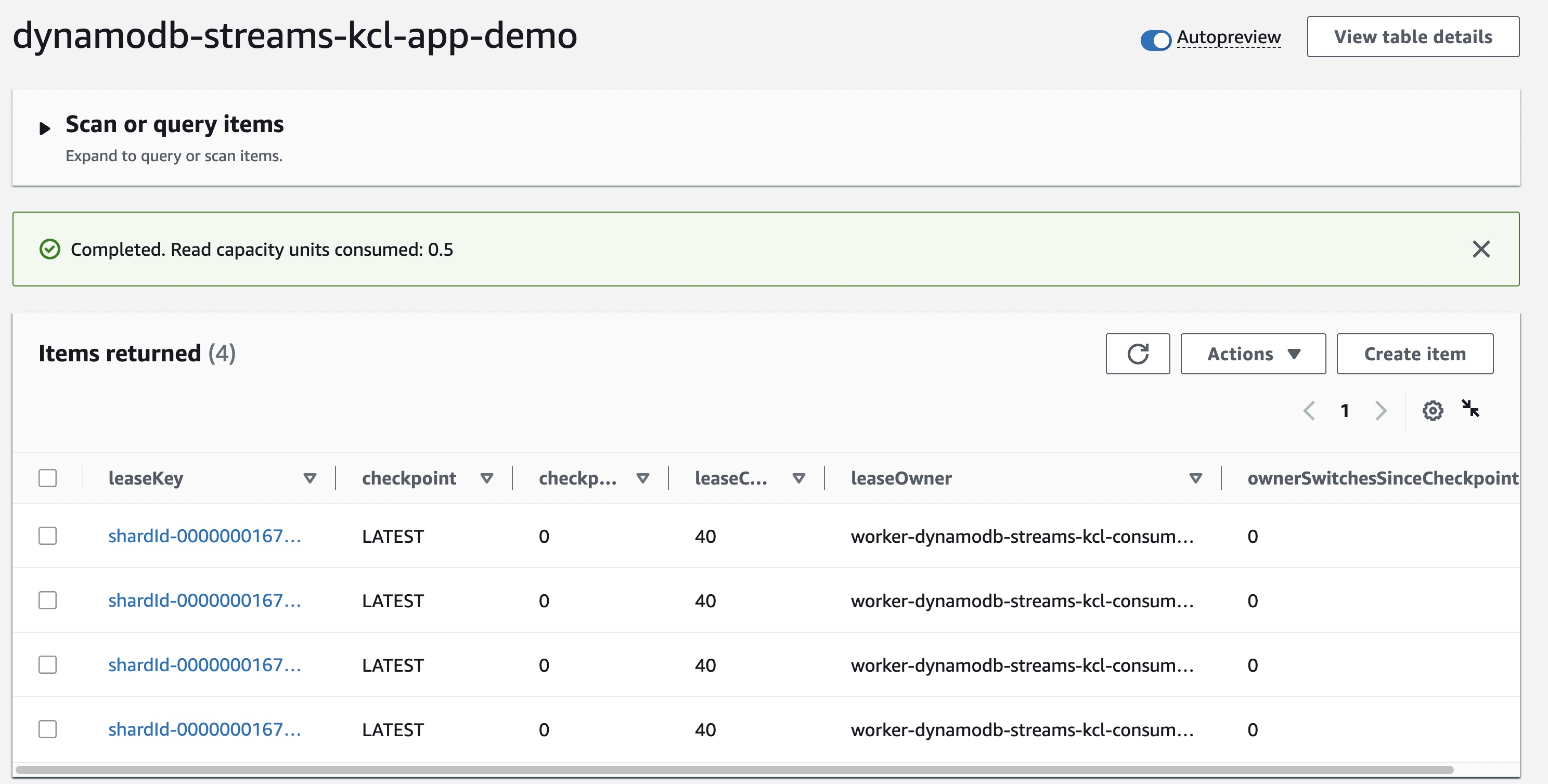
As soon as the rent allocation is whole, test the desk and observe the leaseOwner characteristic:
aws dynamodb describe-table --table-name dynamodb-streams-kcl-app-demo
Upload Knowledge to the DynamoDB Desk
Now that you’ve got deployed the patron software, let’s upload knowledge to the supply DynamoDB desk (customers).
You’ll be able to use the manufacturer.sh script for this.
export export TABLE_NAME=customers
./manufacturer.sh
Take a look at person logs to peer the messages being processed:
kubectl logs -f $(kubectl get po -l=app=dynamodb-streams-kcl-consumer-app --output=jsonpath={.pieces..metadata.call})
Take a look at the goal desk (users_replica) to substantiate that the DynamoDB streams person software has certainly replicated the information.
aws dynamodb scan --table-name users_replica
Understand that the worth for the processed_by characteristic? It is the identical as the patron software Pod. This will likely make it more uncomplicated for us to make sure the end-to-end autoscaling procedure.
Create the KEDA Scaler
Use the scaler definition:
kubectl follow -f keda-dynamodb-streams-scaler.yaml
This is the ScaledObject definition. Understand that it is focused on the dynamodb-streams-kcl-consumer-app Deployment (the only we simply created) and the shardCount is about to 2:
apiVersion: keda.sh/v1alpha1
sort: ScaledObject
metadata:
call: aws-dynamodb-streams-scaledobject
spec:
scaleTargetRef:
call: dynamodb-streams-kcl-consumer-app
triggers:
- kind: aws-dynamodb-streams
metadata:
awsRegion: us-east-1
tableName: customers
shardCount: "2"
identityOwner: "operator"
Observe on shardCount Characteristic:
We’re the usage of the shardCount worth of 2. This is essential to notice since we’re the usage of DynamoDB Streams Kinesis adapter library the usage of KCL 1.x that helps “as much as 2 simultaneous shoppers in step with shard.” Because of this you can not have greater than two person software cases processing the similar DynamoDB flow shard.
Alternatively, this KEDA scaler configuration will be sure that there shall be one Pod for each and every two shards. So, as an example, if there are 4 shards, the applying shall be scaled out to 2 Pods. If there are six shards, there shall be 3 Pods, and so forth. After all, you’ll select to have one Pod for each and every shard by means of environment the shardCount to 1.
To stay monitor of the choice of shards within the DynamoDB flow, you’ll run the next command:
aws dynamodbstreams describe-stream --stream-arn $(aws dynamodb describe-table --table-name customers | jq -r '.Desk.LatestStreamArn') | jq -r '.StreamDescription.Shards | duration'
I’ve used a application referred to as jq. If you wish to have the shard main points:
aws dynamodbstreams describe-stream --stream-arn $(aws dynamodb describe-table --table-name customers | jq -r '.Desk.LatestStreamArn') | jq -r '.StreamDescription.Shards'
Check DynamoDB Streams Shopper Software Auto-Scaling
We began off with one Pod of our software. However, because of KEDA, we must now see further Pods bobbing up mechanically to compare the processing necessities of the patron software.
To verify, test the choice of Pods:
kubectl get pods -l=app=dynamodb-streams-kcl-consumer-app-consumer
In all probability, you’ll see 4 shards within the DynamoDB flow and two Pods. This will exchange (building up/lower) relying at the charge at which knowledge is produced to the DynamoDB desk.
Identical to ahead of, validate the information within the DynamoDB goal desk (users_replica) and observe the processed_by characteristic. Since we’ve scaled out to further Pods, the worth must be other for each and every document since each and every Pod will procedure a subset of the messages from the DynamoDB exchange flow.
Additionally, make sure you test dynamodb-streams-kcl-app-demo keep watch over desk in DynamoDB. You must see an replace for the leaseOwner reflecting the truth that now there are two Pods eating from the DynamoDB flow.

After you have verified the end-to-end resolution, you’ll blank up the sources to keep away from incurring any further fees.
Delete Assets
Delete the EKS cluster and DynamoDB tables.
eksctl delete cluster --name <input cluster call>
aws dynamodb delete-table --table-name customers
aws dynamodb delete-table --table-name users_replica
Conclusion
Use circumstances you must experiment with:
- Scale additional up – How are you able to make DynamoDB streams building up it is choice of shards? What occurs to the choice of person example
Pods? - Scale down – What occurs when the shard capability of the DynamoDB streams decreases?
On this publish, we demonstrated learn how to use KEDA and DynamoDB Streams and mix two tough ways (Exchange Knowledge Seize and auto-scaling) to construct scalable, event-driven techniques that may adapt in response to the information processing wishes of your software.
[ad_2]