

")

")




[ad_1]
A couple of months in the past, I wrote about
my migration from Postgres to SQLite.
I stopped that with a “to be persevered” as a result of I had various problems comparable
to reminiscence and CPU spikes that I could not in point of fact give an explanation for. For some time I believed
it used to be insects in LiteFS (which I am the use of to get allotted SQLite for my
allotted node app), so I scaled right down to a unmarried area or even got rid of
LiteFS for some time however the issue endured so I knew it wasn’t LiteFS, it will have to
were one thing else I did within the means of the migration (there have been reasonably
a couple of adjustments that took place there).
Here is what I am speaking about (recorded and posted
to twitter on
December sixth):
After reluctantly spending a number of hours in this over the previous couple of months (I might
fairly paintings on EpicWeb.dev than my non-public web site), I
in the end discovered what used to be fallacious and I might love to let you know about it.
To get a way for what this web site is, check out the video I had made after I
introduced it:
Learn extra about the options right here
and browse extra about
the structure (at release) right here.
And you’ll take a look at
my web site’s utilization analytics right here. I in most cases get
round 1 / 4 of one million perspectives a month.
One necessary factor so that you can find out about my weblog is that the weblog posts are
written in MDX and compiled at runtime with
mdx-bundler. I do it this manner so
I will be able to trade replace a weblog publish (like repair a typo) and feature the publish up to date in
seconds with no need to redeploy my web site. Most of the people do not do this and
as a substitute collect their weblog posts at construct time so they do not usually run into
the issues I do… Stay that during thoughts.
Additionally helpful to understand that I’ve ~200 weblog posts in this web site plus various
different content material pages which are written in markdown as neatly.
So now that you already know the scope of what we are coping with (now not your
standard blog-pholio mission), here is what we are coping with:
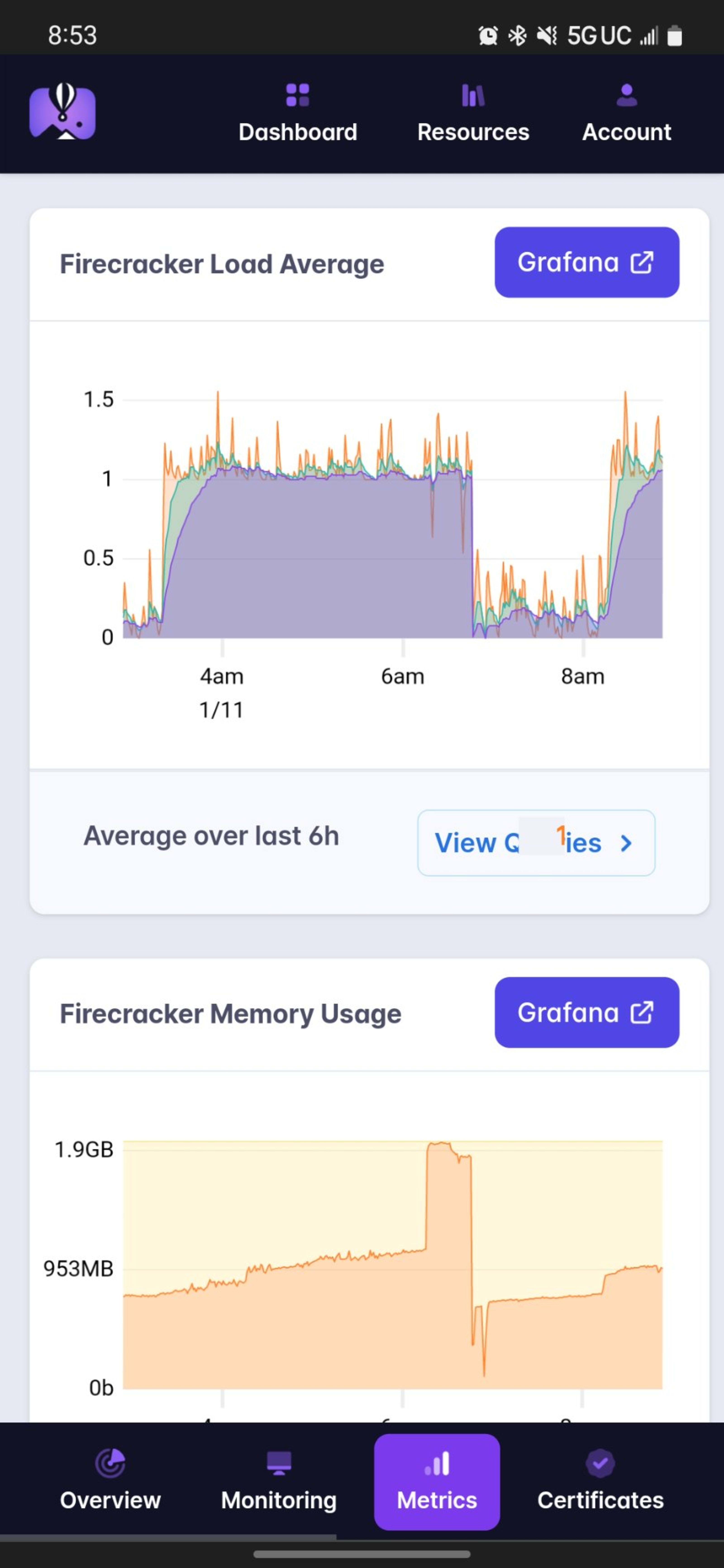
The ones large spikes of reminiscence are if truth be told after I attempted to do something positive about the
downside, however I’m going to get to that during a minute. The principle factor is as soon as that CPU utilization
begins getting out of hand.
Just about after each and every deploy, reminiscence would slowly building up till it hit a
crucial level after which it might spike at the side of an enormous spike in CPU utilization,
throughout which era my app struggled to stay alongside of requests. All the way through those
spikes, other folks would seek advice from my web site and it felt lovely fast now and again, however now not
the whole lot labored reasonably proper. I were given quite a lot of court cases about this. It used to be
in point of fact disturbing.
Logs
The very first thing I attempted used to be saving logs to a document on my computer so I may overview
them to look whether or not there used to be the rest that brought on the spikes:
fly logs -a kcd > ~/Desktop/locker/logs/kcd.$(date +"%YpercentmpercentdpercentHpercentM").logAs a result of I by no means knew when the spike would occur, I’d simply run that on a
laptop and depart it operating after which overview it after the reality. Sure, I do know
that I may and possibly must pipe the ones logs to a couple different provider or one thing
however that is my non-public web site finally. I wish to do as low as imaginable to
stay it operating easily 😅
Sadly, when the spikes did occur, I could not resolve the rest out of
the peculiar from the logs. I attempted including a ton of logging. I even added a
server-timing header to
virtually the whole lot (which is lovely cool, pop open your community tab and test it
out).
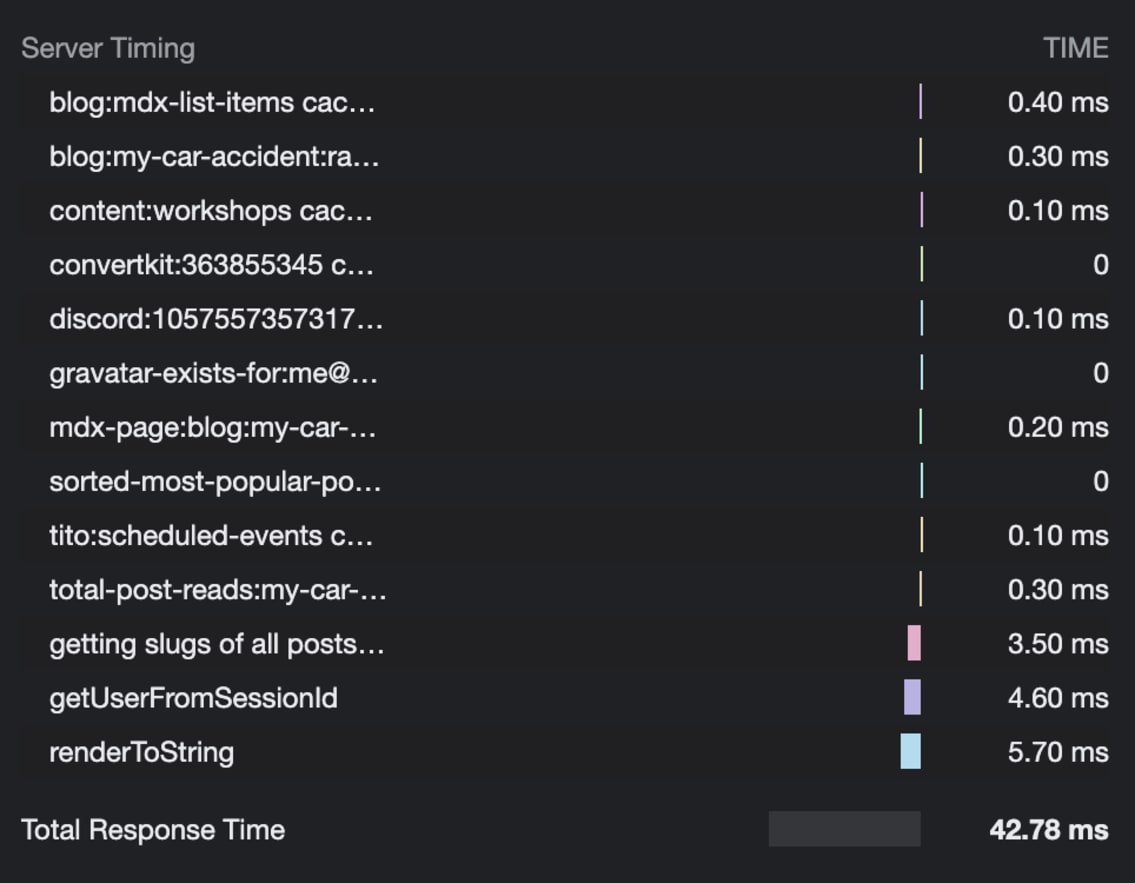
Sadly, the logs weren’t useful in any respect… So, I made up our minds to check out going
deeper…
Heap Snapshots
Heap snapshots are recordsdata that describe the whole lot this is these days in reminiscence.
The Chrome Devtools Reminiscence Tab
has improve for growing and exploring heap snapshots and I have identified reminiscence
problems in browser apps ahead of the use of them. I knew it used to be imaginable to create heap
snapshots in Node.js and cargo the ones into Chrome, so I made up our minds to provide {that a}
take a look at.
Sadly, it may be lovely tough to interpret heap snapshots. As famous
in my video above, I may simply see a couple of problematic issues throughout the heap
snapshot, nevertheless it used to be a problem to seek out what was the reason for them.
To create a snapshot in node, I began with the
heapdump package deal, ahead of knowing that this
capability is built-into Node.js. Now, I’ve a
Remix Useful resource Direction that
creates and downloads the heap snapshot for me. Here is the entire thing:
import trail from 'trail'
import os from 'os'
import fs from 'fs'
import v8 from 'v8'
import {Reaction} from '@remix-run/node'
import {PassThrough} from 'circulate'
import kind {DataFunctionArgs} from '@remix-run/node'
import {requireAdminUser} from '~/utils/consultation.server'
import {formatDate} from '~/utils/misc'
export async serve as loader({request}: DataFunctionArgs) {
look ahead to requireAdminUser(request)
const host =
request.headers.get('X-Forwarded-Host') ?? request.headers.get('host')
const tempDir = os.tmpdir()
const filepath = trail.sign up for(
tempDir,
`${host}-${formatDate(new Date(), 'yyyy-MM-dd HH_mm_ss_SSS')}.heapsnapshot`,
)
const snapshotPath = v8.writeHeapSnapshot(filepath)
if (!snapshotPath) {
throw new Reaction('No snapshot stored', {standing: 500})
}
const frame = new PassThrough()
const circulate = fs.createReadStream(snapshotPath)
circulate.on('open', () => circulate.pipe(frame))
circulate.on('error', err => frame.finish(err))
circulate.on('finish', () => frame.finish())
go back new Reaction(frame, {
standing: 200,
headers: {
'Content material-Sort': 'software/octet-stream',
'Content material-Disposition': `attachment; filename="${trail.basename(
snapshotPath,
)}"`,
'Content material-Period': (look ahead to fs.guarantees.stat(snapshotPath)).measurement.toString(),
},
})
}
The only factor you wish to have to find out about this, is that it’s synchronous and likewise
reasonably sluggish. Additionally, you wish to have two times as a lot reminiscence at the server as what’s being
used as a result of to make a snapshot, v8 must keep a copy of the whole lot in reminiscence
to put it aside to disk. Oh, and it seems that when v8 takes that reminiscence from
your system, it assists in keeping it. I did not know this at the beginning and it kinda freaked me
out:

Somebody know why calling v8.writeHeapSnapshot() (V8 | Node.js v20.3.1 Documentation) would motive my VM to abruptly use two times as a lot reminiscence?
I feel I do know why, however what I do not perceive is why it stays at that degree of reminiscence as a substitute of liberating that reminiscence up as soon as the snapshot is stored
V8 is what you could name a reminiscence hog 🐷 A in point of fact large one.
That is why you notice the ones large spikes within the screenshot I confirmed above. That is
the instant I took a heap snapshot from my telephone. Regularly when this could occur,
it might lead to an out of reminiscence error which is now and again what I used to be making an attempt
to deliberately do to get it to restart when I used to be clear of the keyboard 😅
Oh, and see additionally the look ahead to requireAdminUser(request) bit there. That implies
simplest I will be able to create the ones. Please do not trouble making an attempt.
Something I famous within the video above is that there used to be obviously a subject with a
module referred to as
vscode-oniguruma. Take a look at this
out:
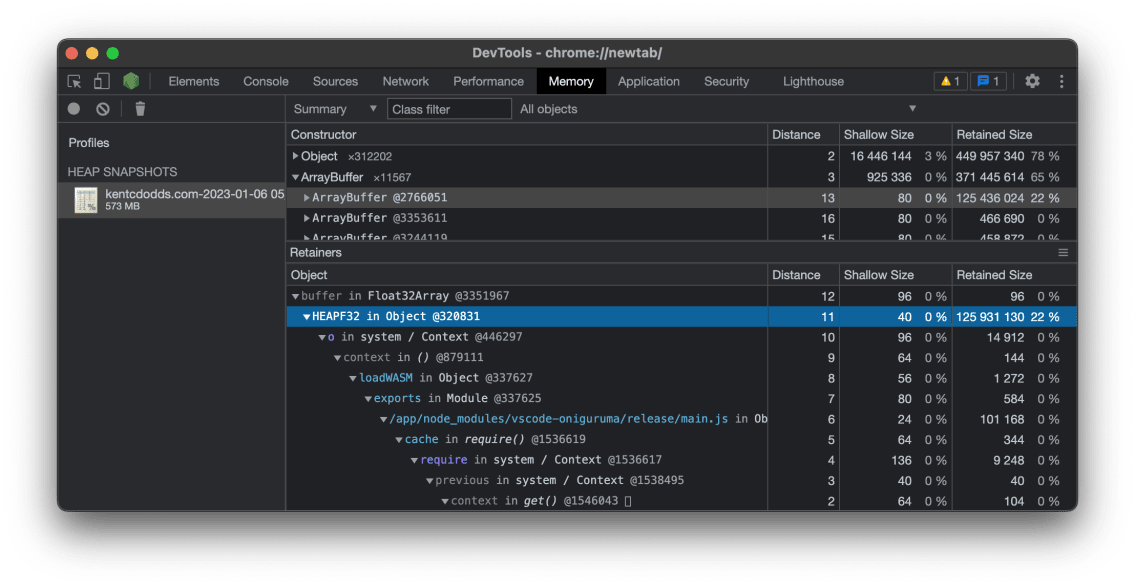
That is an ArrayBuffer (bytes) this is over 125MBs 🤯 One thing is without a doubt
fallacious. After I noticed that, I did not know what used to be fallacious, however I without a doubt knew
one thing used to be up. That module is utilized by a module referred to as
shiki which I exploit in a rehype plugin to
upload syntax highlighting to all my <pre> tags in my weblog posts. It really works in point of fact
neatly and I am proud of it, however it appears it is a bit of a reminiscence hog.
My buddy Ryan additionally makes use of shiki (I borrowed my plugin’s implementation from him),
and recommended I improve the package deal:
I did so and it appeared to assist a bit of, however did not clear up the issue.
Are living circulate with Matteo
So after some time, my buddy Matteo Collina
presented to assist
me debug the problem in a reside circulate. I gave him get right of entry to to the heap snapshots and
he seemed via them with me:
Shiki Repair
Something he spotted proper up entrance used to be the TypedArray allocation used to be nuts:
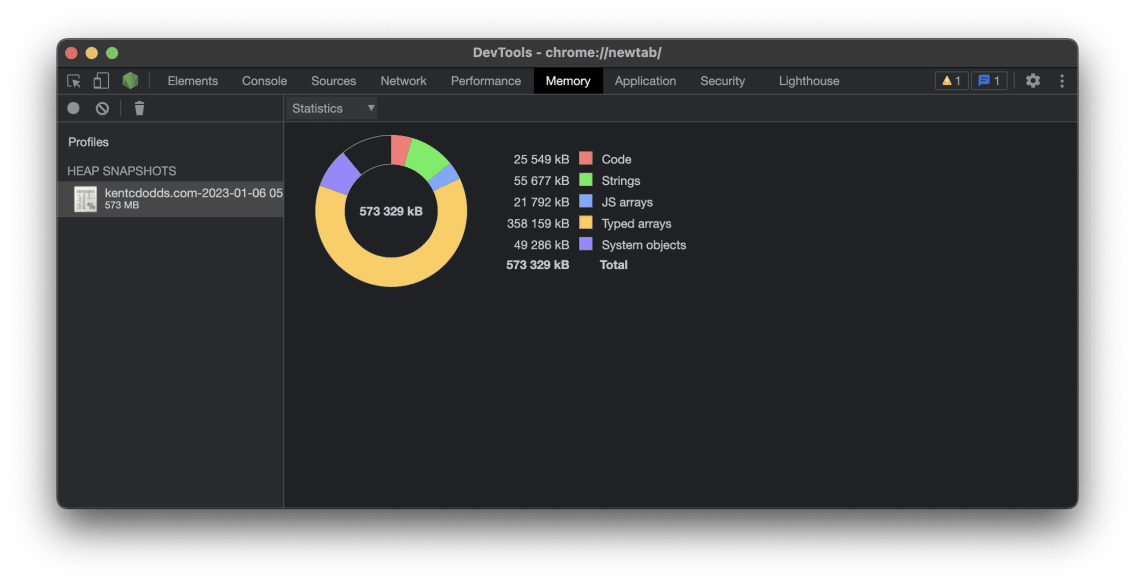
This led him to the HEAPF32 object we might came upon previous and within the circulate he
confirmed me the place that comes from in vscode-oniguruma (it is within the minified constructed
code, now not within the supply code, take a look at grep 😅). It is a WASM factor!!
Within the circulate he confirmed that vscode-oniguruma has an API for cleansing up and
Shiki would possibly not name that correctly. I did not cross an excessive amount of deeper into this
as a result of that simply felt like extra paintings than I sought after to do and as a substitute, we
made up our minds that I may put shiki in a employee thread that may be spun up and down
on call for (every time I want to collect a brand new weblog publish).
So after the circulate, I positioned my shiki utilization in
tinypool like so:
const trail = require('trail')
const {getHighlighter, loadTheme} = require('shiki')
const themeName = 'base16'
let theme, highlighter
module.exports = async serve as spotlight({code, language}) {
theme = theme || (look ahead to loadTheme(trail.unravel(__dirname, 'base16.json')))
highlighter = highlighter || (look ahead to getHighlighter({issues: [theme]}))
const fgColor = convertFakeHexToCustomProp(
highlighter.getForegroundColor(themeName) || '',
)
const bgColor = convertFakeHexToCustomProp(
highlighter.getBackgroundColor(themeName) || '',
)
const tokens = highlighter.codeToThemedTokens(code, language, themeName)
go back {
fgColor,
bgColor,
tokens: tokens.map(lineTokens =>
lineTokens.map(t => ({content material: t.content material, shade: t.shade})),
),
}
}
// The theme if truth be told shops #FFFF${base-16-color-id} as a result of vscode-textmate
// calls for colours to be legitimate hex codes, if they are not, it adjustments them to a
// default, so it is a mega hack to trick it.
serve as convertFakeHexToCustomProp(shade) {
go back shade.change(/^#FFFF(.+)/, 'var(--base$1)')
}
const tinypool = new Tinypool({
filename: require.unravel('./employee.js'),
minThreads: 0,
idleTimeout: 60,
})
// ...
const {tokens, fgColor, bgColor} = (look ahead to tokenizePool.run({
code: codeString,
language,
})) as {
tokens: Array<Array<{content material: string; shade: string}>>
fgColor: string
bgColor: string
}
The minThreads and idleTimeout had been crucial to creating positive that the employee
would spin down when now not in use in order that reminiscence might be reclaimed.
I understand that is simply sweeping the issue underneath the rug, however I have simplest were given so
a lot time to devote to my non-public web site so 🤷♂️
Caching Eval
Every other factor Matteo discovered whilst we had been streaming is that once mdx-bundler
finishes compiling my mdx, the result’s React code that must be evaluated
to generate the weblog publish. So mdx-bundler provides a to hand serve as for that
referred to as getMdxComponent which accepts the code string and returns an element
able to render. Smartly, that is what getMdxComponent does:
const scope = {React, ReactDOM, _jsx_runtime, ...globals}
const fn = new Serve as(...Object.keys(scope), code)
go back fn(...Object.values(scope))
That is proper! new Serve as!! Mainly eval. No, it isn’t evil when used
accurately and it is a just right instance of a right kind utilization 😉 (Simply do not let your
app customers regulate the code that different customers are comparing 😅).
Anyway, one explanation why this is a matter is as a result of each and every request that is available in for a
weblog publish ends up in triggering this code because of this V8 must collect that
string of code and doubtlessly that might hang out. I did not test whether or not
this used to be a real reminiscence leak, however it is without a doubt sub-optimal, so I applied a
easy cache.
Here is ahead of:
serve as useMdxComponent(code: string) {
go back React.useMemo(() => getMdxComponent(code), [code])
}
And here is after:
// This exists so we would not have to name new Serve as for the given code
// for each and every request for a given weblog publish/mdx document.
const mdxComponentCache = new LRU<string, ReturnType<typeof getMdxComponent>>({
max: 1000,
})
serve as useMdxComponent(code: string) {
go back React.useMemo(() => {
if (mdxComponentCache.has(code)) {
go back mdxComponentCache.get(code)!
}
const element = getMdxComponent(code)
mdxComponentCache.set(code, element)
go back element
}, [code])
}
I am the use of lru-cache to ensure this factor
does not develop too large, however I be expecting it by no means will get quite a lot of hundred entries
anyway.
Now not reasonably completed
All the way through the circulate with Matteo, we attempted to breed the issue in the community the use of a
module he made for load trying out referred to as
autocannon. That is vital as a result of issues
like this usually simplest occur you probably have numerous visitors. So autocannon
will simply fireplace a foolish selection of requests at no matter URL you level it to so that you
can simulate manufacturing load.
Sadly, we did not discover a lot more. So after the circulate with Matteo, I
applied the fixes and deployed. Unfortunately, the issue nonetheless endured.
I despatched Matteo a twitter DM and he and I each checked out the most recent heap snapshots
to ensure shiki wasn’t inflicting problems. It wasn’t in there anymore, in order that’s
just right. Matteo did realize I had a bajillion strings in reminiscence. I seemed into the ones
and located numerous strings comparable to precise requests and cloudinary:
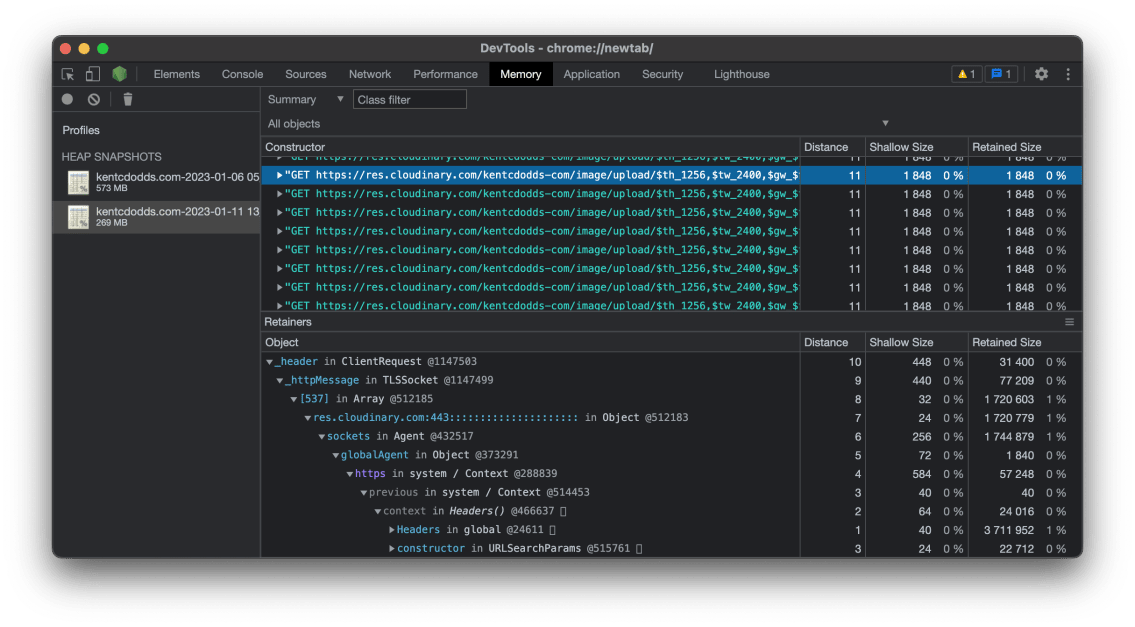
And Matteo advised me he discovered a TON of TLSSocket connections associated with Cloudinary
as neatly:
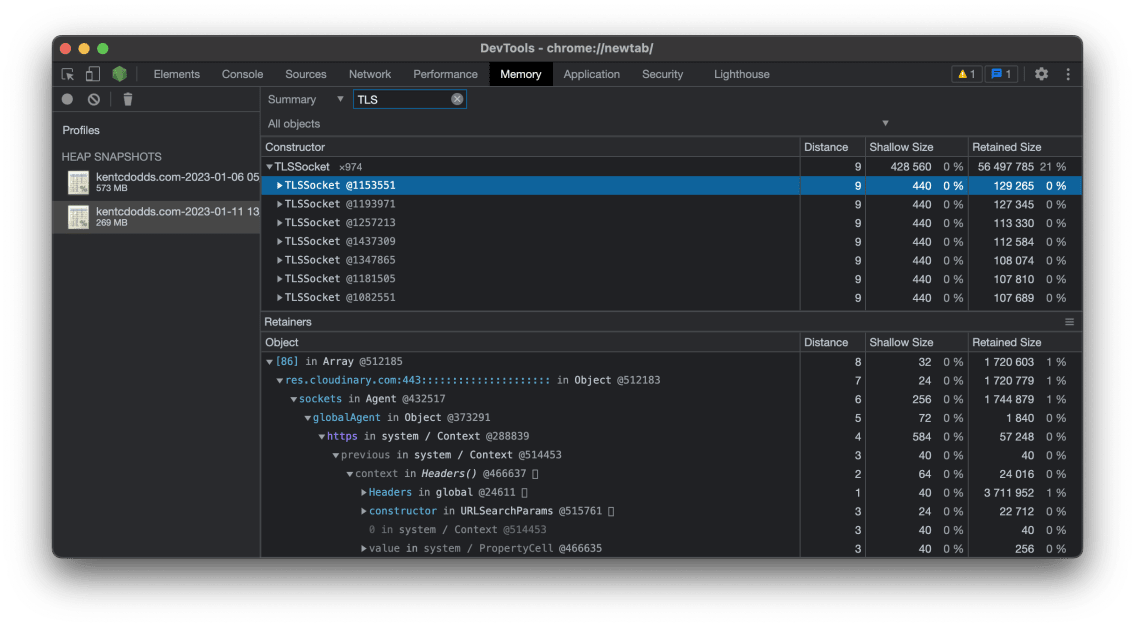
Then he spotted I used to be the use of
express-http-proxy to proxy
my og:symbols for all my pages. I did this some time again for the reason that URLs for
cloudinary to generate the ones at the fly is reasonably lengthy and I believed it might be
higher to only have a easy URL to my very own area after which change into that to the
lengthy cloudinary URL which my server would proxy.
Seems this module used to be leaking like loopy and most likely striking directly to each and every
request object that got here in via it. Most commonly that is twitter/discord/and so on. which
have their very own caches, so it isn’t a TON of visitors, however it is sufficient and the ones
items are reasonably massive.
My resolution used to be to only take away the proxy completely and use the longer URLs. Poof.
After an afternoon of my web site stabilizing at ~500MB of reminiscence utilization, I feel we are
completed with the reminiscence leak. Matteo recommended that I may most likely scale down
and now not revel in any problems as a result of V8 just about takes all of the reminiscence you
give it although it does not in point of fact want it (like I stated… 🐷). So I have scaled it
down from 2GB of reminiscence to 512MB and test this out:
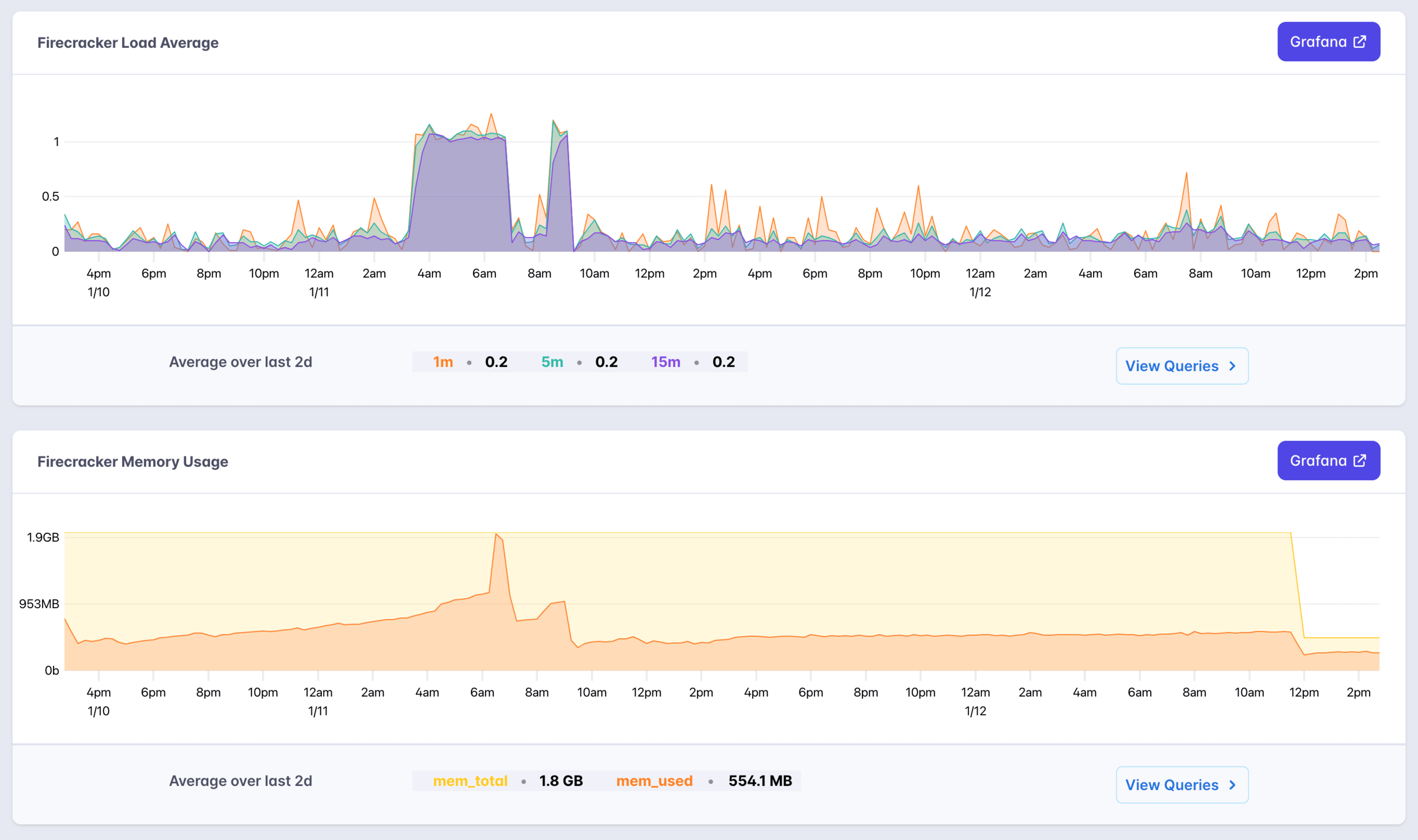
I am taking a look ahead to this two day view to not have the ones CPU and reminiscence
spikes. That surprising drop in reminiscence is after I scaled right down to 512MB and now my app
is sitting thankfully at round 250MB of reminiscence utilization.
I am in point of fact excited to in the end shut the ebook in this one. It makes me really feel just right
to understand that code liable for the reminiscence leaks wasn’t the rest I wrote
myself 😅 I am taking a look ahead to seeking to deploy to more than one areas subsequent week
so we will be able to make this web site lightning speedy regardless of the place you’re on the earth.
I’m hoping this publish used to be useful to you. Giant thanks to Matteo for all of the assist!
[ad_2]


